
Enriching Public Data with LLMs

This is a story of how I used Instructor and OpenAI APIs to enrich public data and build rocklandcounty.info. It's a small but promising example of how LLMs unlock new ways to explore and enrich public data.
My wife and I recently bought a home in Rockland County, NY – a county of 350,000 people located twenty miles north of New York City on the west side of the Hudson. The house was built in the 1960s and is need of some updating. Early in our renovation process we learned that any home improvement contractor doing work in Rockland must be licensed by the county – it's Rockland's way of keeping labor local while sitting next to NYC.
The county publishes a list of all licensed home contractors, but it's not particularly good. Search and filters are limited. Data is minimal and in ALL CAPS. Contact information is strictly analog.
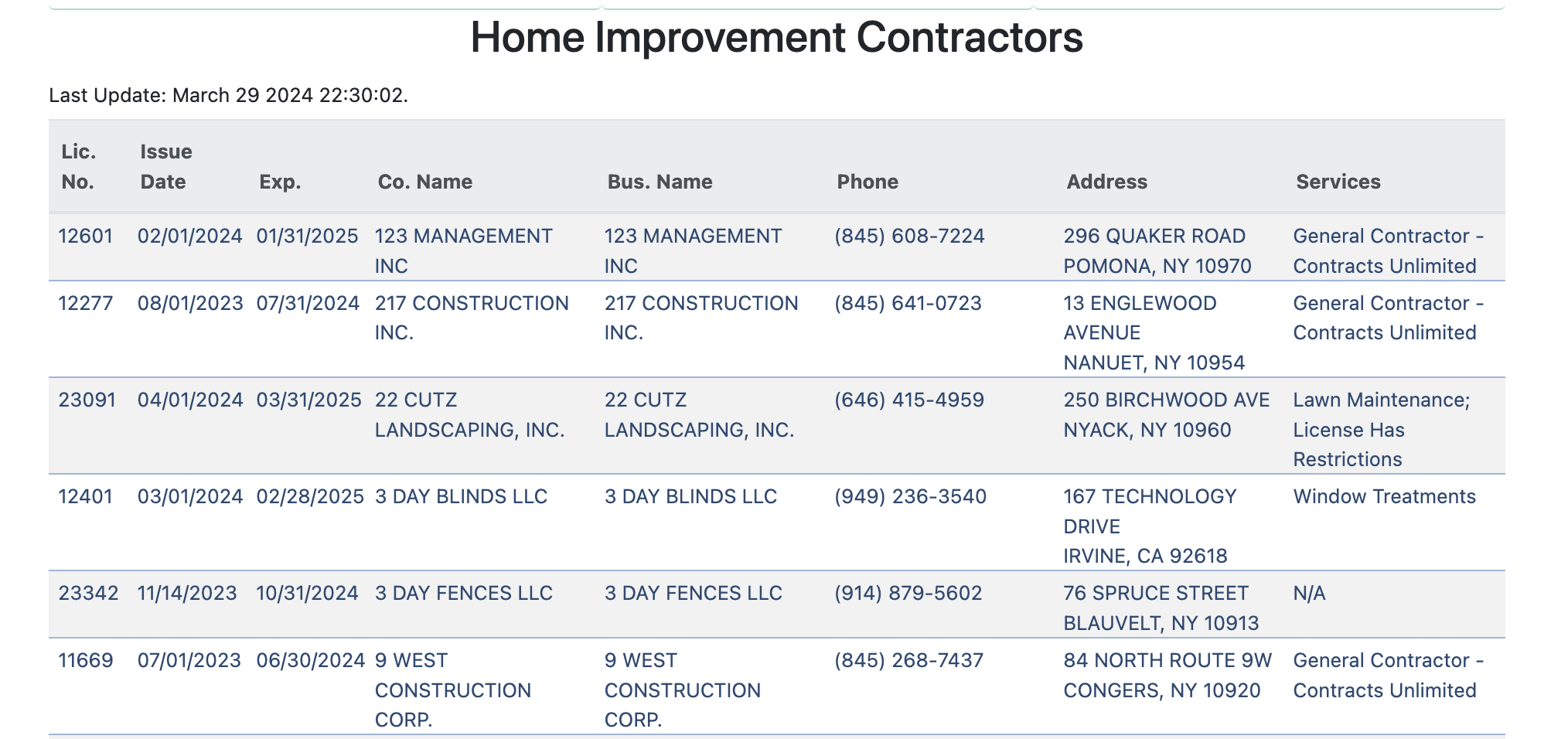
As a software developer in the market to hire numerous home contractors over the next few months, this was too tempting of a dataset to pass up. It's small enough to wrap my head around– about 2,700 contractors – but too big to finesse manually.
I've built a lot of stuff with AI over the last year. Most of my AI projects have used LLMs to generate novel text: choose your own adventures, recipes, RAG applications, etc. Basically: GPT wrappers. But I was recently inspired by Jason Liu's Instructor library and his talk at AI Engineer Summit, Pydantic is All You Need (>155k views at time of writing) to explore a more practical use of LLMs: extracting structured content from unstructured data.
In particular I was intrigued by the question: what can I do with public data today that I couldn't do before LLMs?
Fancy Titlecase
First task with Rockland County's contractor data: de-CAPS it.
I simply want to convert the company name and address from UPPER CASE to Title Case. Python has a .title() method that naively capitalizes the first letter in a "word" (a group of characters bounded by whitespace) and lower cases everything that follows, but that simple algorithm results in names like:
Dj Helmke Landscaping
Ds Mechanical Systems Llc
Lbr Electric, Inc.You and I can look at this and immediately tell something is wrong: DJ, DS, LBR, LLC – these are all acronyms that should be capitalized. We could hardcode rules for the common acronyms, like LLC, but it's hard to write a regex to describe: "If it's 2-3 letters at the beginning of the name that don't form a word..."
You can do it with an LLM though:
def title_case_with_gpt(name):
msg_str = f"""{name}
Convert this Business Name from ALL CAPS to Title Case.
Keep known abbreviations like LLC uppercase.
If a name begins with 2-3 letters that don't form a word, this is prombably an abbreviation that should remain all caps.
Examples:
DS MECHANICAL SYSTEMS LLC -> DS Mechanical Systems LLC
EMFO CONTRACTORS, INC. -> EMFO Contractors, Inc.
JDK HEATING & COOLING, INC. -> JDK Heating & Cooling, Inc.
JOY HEATING & AIR CONDITIONING INC. -> Joy Heating & Air Conditioning Inc.
LBR ELECTRIC, INC. -> LBR Electric, Inc.
"""
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": msg_str}],
)
new_name = response.choices[0].message.content.strip()
return new_nameRunning this script against 2,700 contractors took about 15 minutes and cost less than $2. The results were pretty good. Not 100%, but better, faster, and cheaper than any other method. Also, it works surprisingly well with GPT 3.5 Turbo, which fast and cheap compared to GPT 4 Turbo.
And though I'm using OpenAI's API's here, this kind of data processing is also a great usecase for a locally run open-source LLM: you don't need persistent connectivity to your LLM, you don't particularly care how fast it responds, and you can run it once and reap the rewards of the results forever.
Which website is it?
Rockland's public data only contains a company name, phone number, and a street address. I want websites and emails.
Now, it should be noted that many of these contractors don't have websites.
SerpAPI offers an API that lets you do a Google search and get back results as JSON. I wrote a script to iterate through contractors and search for {company_name} {phone_number}, figuring that any official website should have both of these.
One tip when making expensive (money or time) API requests: first save the results to file and then process them from disk so you don't have to re-request later.
def get_serps_for_contractor(contractor):
query = f"{contractor.company_name} {contractor.phone_number}"
params = {
"api_key": os.environ.get("SERP_API_KEY"),
"engine": "google",
"q": query,
"location": "New York, United States",
"google_domain": "google.com",
"gl": "us",
"hl": "en",
}
search = serpapi.search(params)
with open(f"data/serps/serps_{contractor.license_number}.json", "w") as json_file:
json.dump(search.data, json_file, indent=4)
return TrueOnce this script ran, I had a directory containing search results for 2,700 contractors. Now the question was: for any given contractor, which domain – if any – is likely to be the company's official website?
I compiled a set of common domains that appear in multiple search results and got something like this:
...
fastpeoplesearch.com: 250
clustrmaps.com: 254
m.yelp.com: 268
zoominfo.com: 318
thebluebook.com: 353
yellowpages.com: 403
m.facebook.com: 455
buzzfile.com: 504
safer.fmcsa.dot.gov: 847
bbb.org: 893
manta.com: 906
yelp.com: 974
mapquest.com: 1074
facebook.com: 1329
buildzoom.com: 1491For each contractor, I excluded these common domains and any others that don't end in .com – this was a quick hack to filter out various government domains, while taking a calculated risk that my local plumber doesn't have a .ly, .io, or .ai domain. (I may revisit this hypothesis later.)
def get_candidate_sources(c):
with open('data/common_domains.txt', 'r') as f:
common_domains = f.read().splitlines()
candidates = []
for s in c.sources:
if s.domain not in common_domains \
and s.domain.count(".") == 1 \
and s.domain.split(".")[-1] == "com":
candidates.append(s)
return candidates
I passed each candidate domain along with its page title and snippet to GPT, and asked it to return the domain most likely to be the official website for the company. Here early tests with GPT 3.5 Turbo were far less promising, so I stuck with GPT 4 Turbo.
def get_homepage(c):
candidates = get_candidate_sources(c)
domain = None
if candidates and c.company_name != "N/A":
data = []
for s in candidates:
data.append(
{"domain": s.domain,
"snippet": s.snippet,
"title": s.title,
"url": s.url}
)
data_str = json.dumps(data)
msg_str = f"""These are search results for a business.
return the domain that is the official website for the company.
the domain should be the official business url.
the domain should have some resemblance to the company name
Only return the official business url.
If none of the domains are the official website, return None
Here are examples:
.... ommitted for brevity....
Company Name: {c.company_name}
Search Results: {data_str}"""
client = OpenAI()
result = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[{"role": "user", "content": msg_str}],
)
domain = result.choices[0].message.content
return domainOn the first pass, GPT 4 found a domain for every single company! Absolutely incredible!!! Especially considering that.... many of these contractors don't have a website.
After a few 404s, I realized that GPT had hallucinated domains where it couldn't find one from the list. This was a problem with accepting an open-ended string as a result.
On my next iteration, I gave each domain an index and used Instructor to force GPT to return the index of the domain it thought was most likely, or 999 if it couldn't find one.
def get_homepage(c):
candidates = get_candidate_sources(c)
url = None
if candidates and c.company_name != "N/A" and not c.url:
data = []
for i, s in enumerate(candidates):
data.append(
{"domain": s.domain,
"snippet": s.snippet,
"title": s.title,
"url": s.url,
"index": i }
)
data_str = json.dumps(data)
msg_str = f"""These are search results for a business.
Return the index of the domain that is the official website of the business.
The domain should have some resemeblance to the business name.
Do not return a domain that is a directory or aggregator website.
Only return the official business url.
If none of the domains are the official website, return 999.
Here are examples:
.... ommitted for brevity....
Return the index of the domain that is the official website of this business and search results:
Company Name: {c.company_name}
Search Results: {data_str}"""
class Domain(BaseModel):
index: int
client = instructor.patch(OpenAI())
domain = client.chat.completions.create(
model="gpt-4-turbo-preview",
response_model=Domain,
messages=[{"role": "user", "content": msg_str}],
)
try:
if domain.index != 999:
url = data[domain.index]["domain"]
print(c.company_name, url)
else:
print(c.company_name, "No official website found.")
except Exception as e:
print(c.company_name)
print(e)
return urlWhat's happening here?
I defined a Pydantic model, Domain, which has a single attribute: index. Instructor patches OpenAI's helper library, enforces Function Calling, and ensures that I get a well formatted response in the type of my Pydantic response_model, Domain.
Now I don't have to do any loosey-goosey string parsing from OpenAI – Instructor ensures that I'll get back a properly typed Domain object with an integer every time.
Running this script against 2,700 domains took a few hours and cost about $15. The results were, again, pretty good. Not perfect: GPT4 identified waze.com as the official domain for B & P Custom Granite – but it's pretty good.
While I suppose there are ways that you could write heuristics that say something like, "does this domain contain X% of the same letters as this name?," you end up going down deep pattern matching rabbit hole. "Choose the most likely option from this list," feels like a new tool in my coding tool belt.
Publishing the Results and What's Next
You can view the results of what I've got so far at rocklandcounty.info.
This site is a Jekyll site deployed on Cloudflare Pages. It makes heavy use of Jekyll's data files feature and a 16mb JSON file of contractor data. Compare the results against the original for a feel of the value-added by LLM data-enrichment and a little bit of UX intentionality. And, in the interest of being balanced, you can also try to find some of the domain identification mistakes that I haven't cleaned up yet.
On that point – misinformation is a legitimate concern with any data GPT touches (humans too, for that matter!) My next step is to programmatically visit each url and verify that the domain actually is correct. My mental model is something like a peer-review: have one GPT app identify the information, have another GPT verify that the information is accurate – though I suspect a simple grep of the page title and homepage copy will suffice most of the time.
My first attempt at this ran into a high-number of 503 Forbidden, so I either need to get more sophisticated with my scraping, or do it manually. Once I have verified the domains, I'll try to extract email addresses and more company information. I expect to lean on Instructor more heavily in these steps to do what it was designed to do: extract structured information from unstructured text.
For now, I went ahead and published early to start getting the site indexed by Google. The sitemap shows 2,700 pages – and Google indexes at most 300 urls per day. 72 hours after submitting it for indexing, I'm starting to see a little bit of traffic on phrases I care about:
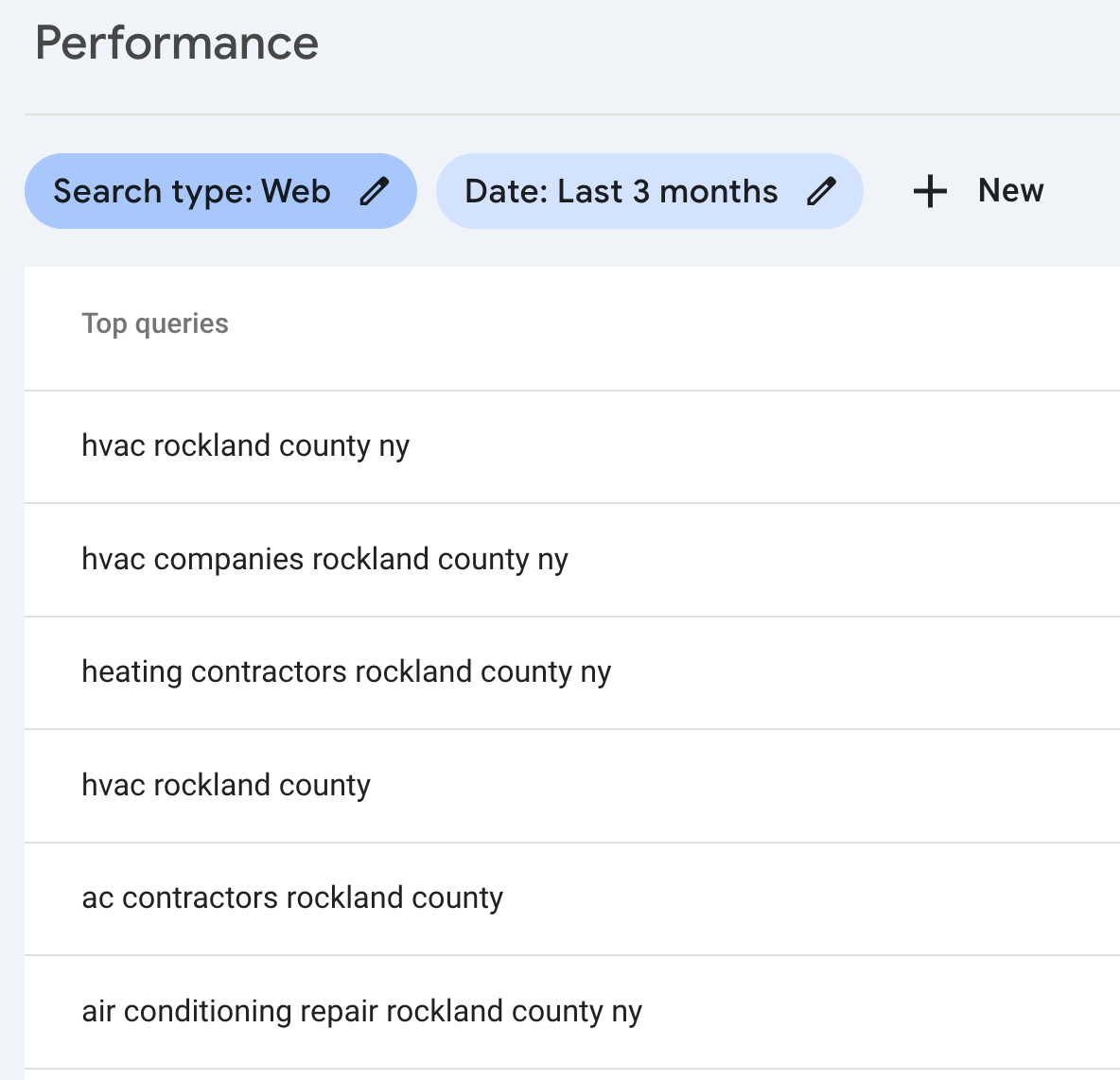
Rockland County Info is a fast static site that provides novel utility to a niche audience. It's got some SEO intentionality and a lot of long-tail landing pages. I like it's longterm prospects against the search competition.
This is a project that I wouldn't have tackled were it not for the new capabilities that LLMs unlock. The fancy titlecase alone was a big win – I was never going to put my name on a website full of ALL CAPS data.
Ben Stein wrote a great blog post in which he identified a pattern for when you might want to use an LLM in your code: look for tasks that are "easy for humans but hard for code." In these two examples, I'm asking my code to make a judgment call – something that was hard to do before LLMs.